
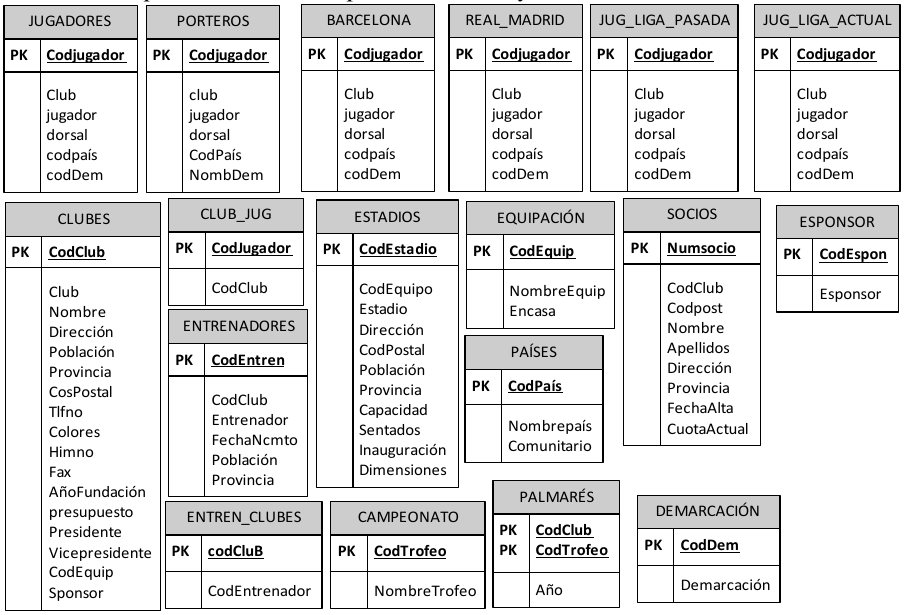
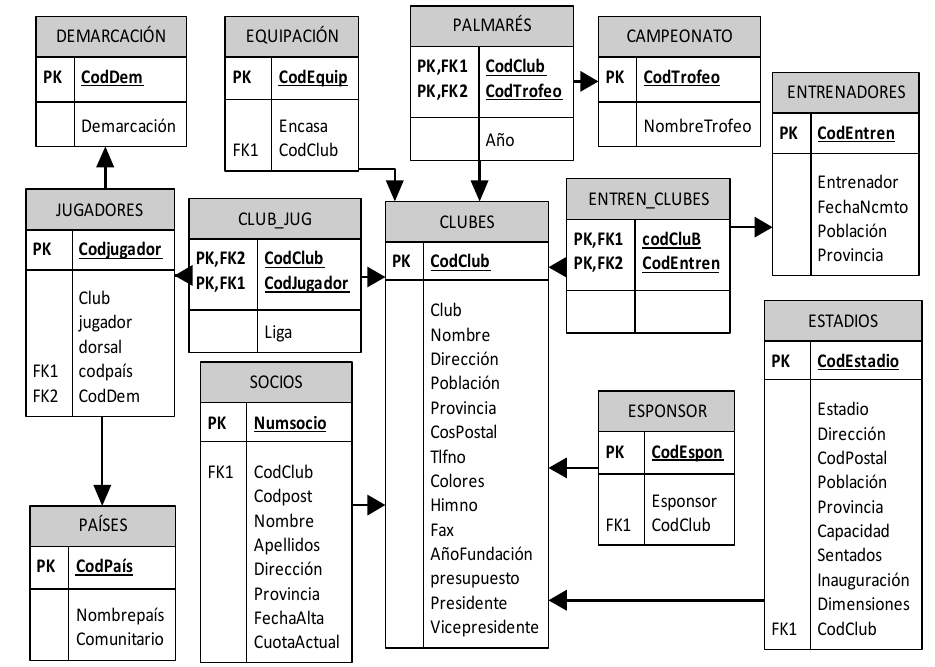
1.3.1. Introducción
Los predecesores de los sistemas gestores de bases de datos fueron los sistemas gestores de ficheros o sistemas de archivos tradicionales.
- Archivos tradicionales. Consiste en almacenar los datos en archivos individuales, exclusivos para cada aplicación particular. En este sistema los datos pueden ser redundantes (repetidos innecesariamente) y la actualización de los archivos es más lenta que en una base de datos.
- Base de datos. Es un almacenamiento de datos formalmente definido, controlado centralmente para intentar servir a múltiples y diferentes aplicaciones. La base de datos es una fuente de datos que son compartidos por numerosos usuarios para diversas aplicaciones.
Así, en un Sistema de archivos tradicional la información está dispersa en varios ficheros de datos y existe un cierto número de programas que los recuperan y agrupan. Aunque los sistemas de ficheros o archivos supusieron un gran avance sobre los sistemas manuales, tienen inconvenientes bastante importantes que se solventaron, en gran medida, con la aparición de los sistemas de bases de datos.
1.3.2. Evolución y tipos de base de datos
Coincidiendo con la evolución histórica de las bases de datos éstas han utilizado distintos modelos:
- Jerárquicos
- En red.
- Relacionales.
- Multidimensionales.
- De objetos.
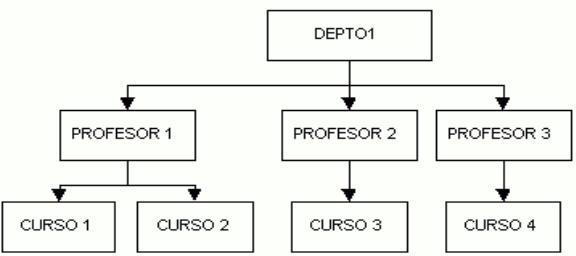
1.3.2.1. Bases de Datos con estructura jerárquica
La estructura jerárquica fue usada en las primeras BD. Las relaciones entre registros forman una estructura en árbol. Actualmente las bases de datos jerárquicas más utilizadas son IMS de IBM y el Registro de Windows de Microsoft.
1.3.2.2. Bases de Datos con estructura en red
Esta estructura contiene relaciones más complejas que las jerárquicas. Admite relaciones de cada registro con varios que se pueden seguir por distintos caminos.
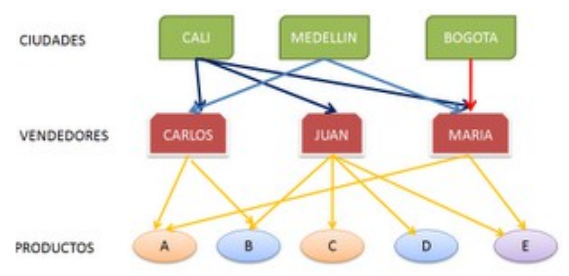
El inventor de este modelo fue Charles Bachman, y el estándar fue publicado en 1969 por CODASYL.
1.3.2.3. Bases de Datos con estructura relacional
La estructura relacional es la más extendida hoy en día. Almacena los datos en filas o registros (tuplas) y columnas o campos (atributos). Estas tablas pueden estar conectadas entre sí por claves comunes.
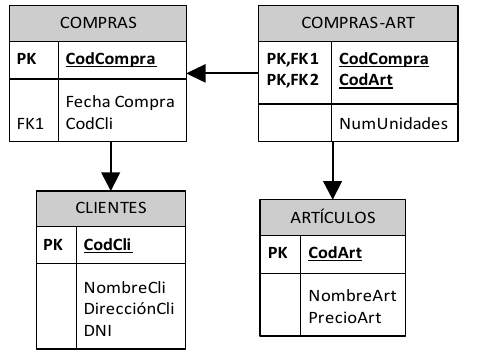
En este libro nos centramos en el estudio de bases de datos relacionales.
1.3.2.4. Bases de Datos con estructura multidimensional
La estructura multidimensional tiene parecidos a la del modelo relacional, pero en vez de las dos dimensiones filas-columnas, tiene N dimensiones. Esta estructura ofrece el aspecto de una hoja de cálculo.

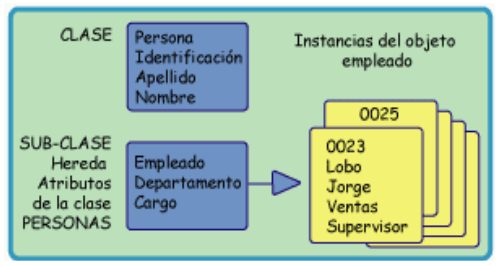
1.3.2.5. Bases de Datos con estructura orientada a objetos
La estructura orientada a objetos está diseñada siguiendo el paradigma de los lenguajes orientados a objetos. De este modo soporta los tipos de datos gráficos, imágenes, voz y texto de manera natural. Esta estructura tiene gran difusión en aplicaciones web para aplicaciones multimedia.
1.3.3. Sistemas de ficheros tradicionales
En estos sistemas, cada programa almacenaba y utilizaba sus propios datos de forma un tanto caótica. La única ventaja que conlleva esto es que los procesos son independientes, por lo que la modificación de uno no afecta al resto.
Pero tiene grandes inconvenientes:
- Datos redundantes. Ya que se repiten continuamente.
- Coste de almacenamiento elevado. Al almacenarse varias veces el mismo dato en distintas aplicaciones, se requiere más espacio en los discos.
- Tiempos de procesamiento elevados. Al no poder optimizar el espacio de almacenamiento.
- Probabilidad alta de inconsistencia en los datos. Ya que un proceso cambia sus datos y no el resto. Por lo que el mismo dato puede tener valores distintos según qué aplicación acceda a él.
- Difícil modificación en los datos. Debido a la probabilidad de inconsistencia, cada modificación se debe repetir en todas las copias del dato (algo que normalmente es imposible).
En la siguiente figura se muestra un sistema de información basado en ficheros. En ella se ve que la información aparece inconexa y redundante.
1.3.4. Sistemas de base de datos relacional
En este tipo de sistemas los datos se centralizan en una base de datos común a todas las aplicaciones. Estos serán los sistemas que estudiaremos en este curso.
Sus ventajas son las siguientes:
- Menor redundancia. No hace falta tanta repetición de datos. Aunque, sólo los buenos diseños de datos tienen poca redundancia.
- Menor espacio de almacenamiento. Gracias a una mejor estructuración de los datos.
- Acceso a los datos más eficiente. La organización de los datos produce un resultado más óptimo en rendimiento.
- Datos más documentados. Gracias a los metadatos que permiten describir la información de la base de datos.
- Independencia de los datos y los programas y procesos. Esto permite modificar los datos sin modificar el código de las aplicaciones.
- Integridad de los datos. Mayor dificultad de perder los datos o de realizar incoherencias con ellos.
- Mayor seguridad en los datos. Al limitar el acceso a ciertos usuarios.
Como contrapartida encontramos los siguientes inconvenientes:
- Instalación costosa. El control y administración de bases de datos requiere de un software y hardware potente.
- Requiere personal cualificado. Debido a la dificultad de manejo de este tipo de sistemas.
- Implantación larga y difícil. Debido a los puntos anteriores. La adaptación del personal es mucho más complicada y lleva bastante tiempo.
En la siguiente figura se muestra un sistema de información basado en bases de datos. La información está relacionada y no es redundante.
1.3.5. Ejemplo de archivos tradicionales
Se cuenta con dos archivos: CLIENTES y FACTURAS.
El primer archivo tiene los datos básicos de los clientes, mientras que en el segundo se almacenan las ventas realizadas. Al emitir cada factura se ingresan nuevamente los datos num, nombre, domicilio.
| Num | Nombre | Dirección | Teléfono | FechaNacimiento | |
|---|---|---|---|---|---|
| 1225 | Juan García | Guaná 1202 | 985674863 | 13/08/1972 | jgarcia@adinet.com |
| 1226 | Fernando Martínez | Rincón 876 | 984568643 | 23/02/1987 | fmar@gmail.com |
| … | … | … | … | … | … |
| Num | Nombre | Dirección | Producto | Precio |
|---|---|---|---|---|
| 1225 | Joaquín García | Guaná 1202 | Azulejos | 1250 |
| 1226 | Fernando Martínez | Rincón 876 | Pintura | 900 |
| … | … | … | … | … |
Desventajas:
- Se presentan redundancias de datos (datos repetidos innecesariamente: nombre, dirección). Se duplican esfuerzos.
- Se pueden producir contradicciones entre los datos, si por ejemplo se ingresan nombres diferentes para un mismo cliente (Juan por Joaquín).
No hay comentarios.:
Publicar un comentario